
The most common failure mode I've seen in AI-assisted builds is simple to describe and hard to avoid: push fast, accept everything, end up with a mess. The symptoms are predictable. Formulas that look right but have subtle errors - a default value set to the wrong threshold, a weighting factor applied twice in the cascade, an off-by-one error in a loop nobody reviewed. UI that's technically functional but feels wrong - the right elements in the wrong hierarchy, interactions that make no sense to an unfamiliar user, visual inconsistencies that accumulate into a sense of shoddiness. A codebase that's hard to trust because no human ever fully read it, hard to debug because the AI that wrote it no longer remembers the context, and hard to extend because nobody knows what assumptions are baked where.
I did this once. Burned a month on it. The outcome was worse than no product - it was a product that looked complete from the outside and was irredeemable from the inside. Every bug fix revealed two more. Every feature extension broke three existing behaviours. The codebase was large enough to feel like progress and shallow enough to be worthless. I shelved it and started over.
The restart was slower on paper and dramatically faster in practice, because the discipline was inverted.
The principle: slow upstream, fast downstream
The lesson from the failed attempt was that speed during writing is worthless if the spec isn't locked. The AI isn't a junior engineer who will push back on an ambiguous requirement; it's a compliance engine that will produce something plausible for whatever you give it. If the requirement is vague, the implementation will be vague in ways that look specific. The only way to get usable output is to make the input unambiguous, which means the spec work has to happen before any code is generated.
Concretely, this meant three artefacts had to exist before a single line of code was written for any screen. A formula register - every calculation in the platform defined with inputs, outputs, weights, failure conditions, confidence rules, and worked examples. A screen inventory - every screen described with exhaustive detail: what data it reads, what actions it offers, what happens on each action, what role sees what, what the error states look like. A design system - every visual element tokenised, every interaction pattern defined, no improvisation allowed. Together, these three documents are the spec. The AI generates code against the spec, not against a conversation.
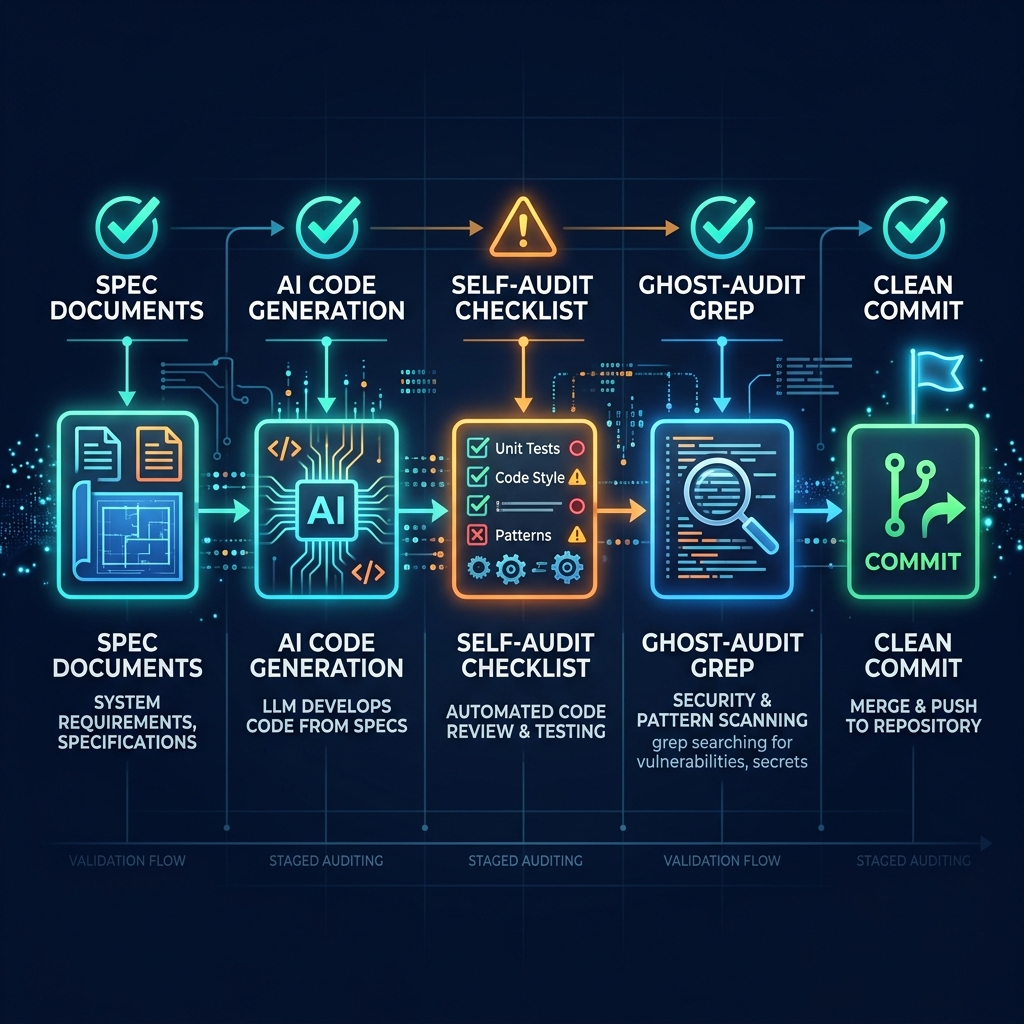
This shifts the bottleneck from code generation to spec validation, which is exactly where it should be. Validating a formula takes minutes. Validating a generated implementation of that formula takes hours, because you have to reverse-engineer what the AI thought the formula was. Ten minutes checking that the DSR turnover rate default is 10% (not 40%) before the code is written saves the two days of debugging when a territory's P&L mysteriously overstates by 30% because of a compounding error nobody can locate.
The self-audit protocol
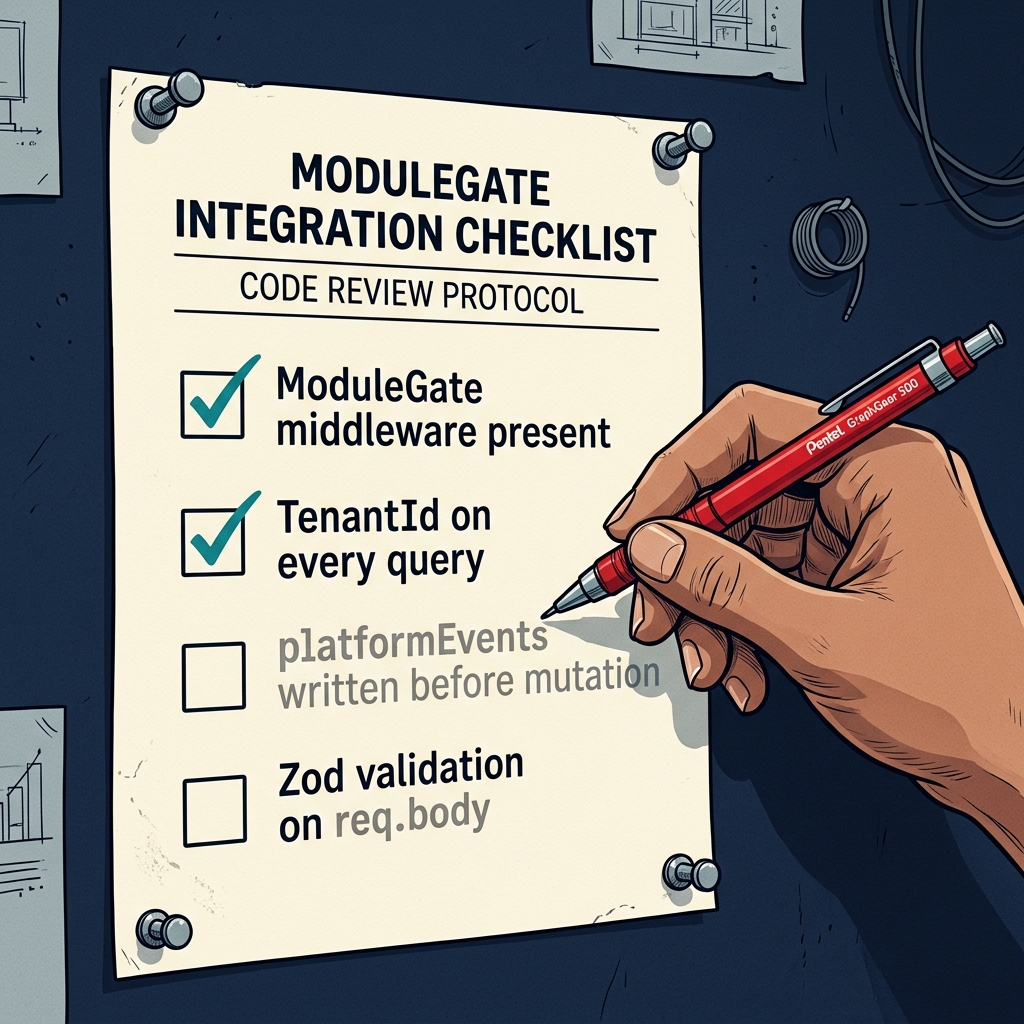
Even with a locked spec, AI-generated code drifts. It invents field names that weren't in the schema. It hardcodes values that were supposed to be configurable. It skips middleware that was mandatory. The defence is a standardised self-audit the AI runs after every build, checking its own work against a fixed list.
Every route must have the module-access check before any other logic. Every database query must include the tenant identifier as a filter. Every state-changing action must write to the platform events log before the database mutation it gates. Every request body must be validated with a schema. Every import path must match the project structure. Every override of a schema default must be applied explicitly in code with a comment explaining why.
The audit isn't subtle. It's a checklist. The AI greps its own code for the checks that should be present, confirms them, and reports any misses. If anything fails, the fix goes in a separate commit from the feature, so the audit trail is clean. If critical issues emerge, they're resolved before the frontend is built on top, because debugging the back after the front is in place is a nightmare.
A separate ghost audit grep for patterns that should not exist - old middleware names from previous architectures, environment variable flags that have been replaced with database-driven gates, file references that should have been deleted. The AI invents drift over a long project. The ghost audit catches it when it's cheap to fix.
The psychological angle
There's a human factor that matters as much as the technical protocols. When you're using an AI to build quickly, the temptation is to accept outputs that are 90% right and move on. The missing 10% compounds. After thirty accepted 90%-right outputs, the codebase is 3% right - and you have no idea which 3%.
The discipline is to treat every AI output as a prompt for your own validation, not as a completed deliverable. The AI's job is to draft. Your job is to read, validate, correct, and commit. If you're skimming rather than reading, you're accumulating debt. If you're accepting rather than validating, you're building the same disaster I built the first time. The fact that the AI is fast doesn't mean the project can be fast. It means the human bottleneck moves from writing to validating, and the total time is determined by how fast you can validate without skimming.
What the discipline looks like in practice
A typical build session for a single screen might look like this. Read the screen inventory spec for the screen. Cross-reference the formulas it uses against the formula register. Confirm every field name against the schema. Ask the AI to draft the backend routes. Review the draft for invented fields, hardcoded values, missing middleware. Correct or reject. Ask the AI to run the self-audit. Review the audit results. Fix any flagged issues. Commit the backend. Only then proceed to the frontend.
This is slow. A single screen might take four to six hours. It's also the only way the output is trustworthy. The temptation to batch multiple screens into a single session, or to skip the self-audit "just this once", is where disasters start. The discipline has to be mechanical, because your willpower will break long before the project is done.
The final output of the discipline isn't just a working product. It's a codebase you can actually reason about, change with confidence, and hand to another engineer without apology. That's worth a month of apparent slowness over a year of delivery. Nothing about AI velocity changes the fact that software is a durable artefact, and durable artefacts deserve the time it takes to build them well.